In this joint work with Vikram Voleti and Christopher Pal, we show that a single diffusion model can solve many video tasks: 1) interpolation, 2) forward/reverse prediction, and 3) unconditional generation through a well-designed masking scheme 🧙♂️.
See our website, which contains many videos: https://mask-cond-video-diffusion.github.io. The paper can be found here. The code is available here: https://github.com/voletiv/mcvd-pytorch.
A lot of the existing video models have poor quality (especially on long videos), require enormous amounts of GPUs/TPUs, and can only solve one specific task at a time (only prediction, only generation, or only interpolation). We aimed to improve on all these problems. We do so through a Masked Conditional Video Diffusion (MCVD) approach.
Using score-based diffusion, we get very high quality and diverse results that retain their quality better over time (as shown in Figure 1 below) due to the Gaussian noise injection of such models.

To allow our models to solve more than a single task, we devise a masking approach. We condition on past and future frames to predict current frames. During training, we independently mask all the past frames or
all the future frames. The magic ✨ here is that during testing, we can mask past and/or future frames to do interpolation, prediction, or generation! 🤯 See Figure 2 below for more details.
- future/past prediction: when only future/past frames are masked
- unconditional generation: when both past and future frames are masked
- interpolation: when neither past nor future frames are masked.

This means that a single general model can solve multiple tasks! To further be able to generate long sequences, we use autoregressive block-wise predictions to generate more frames than the number of current frames. See Figure 3 below; conditioning on 2 previous frames, we generate 5 current frames and use the last two generated ones to generate another 5 frames.

With MCVD, we obtain state-of-the-art performance on many datasets on tasks such as interpolation and prediction without training specialized models made for these specific tasks! 🙀 We highlight some of our most exciting results below (for the actual videos, see the website):
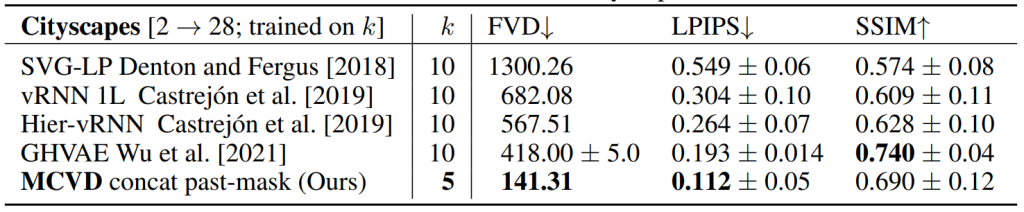
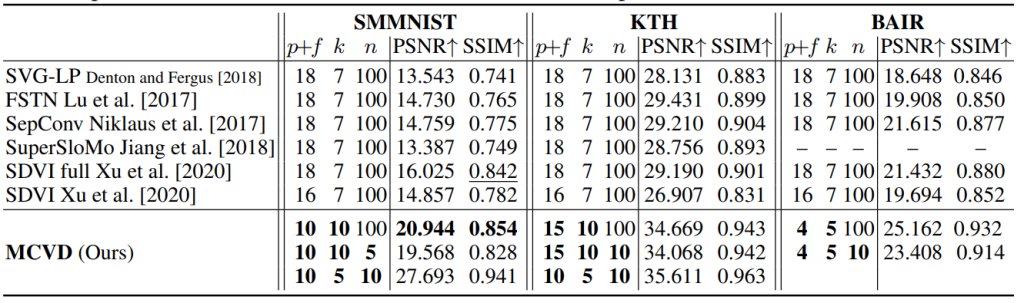
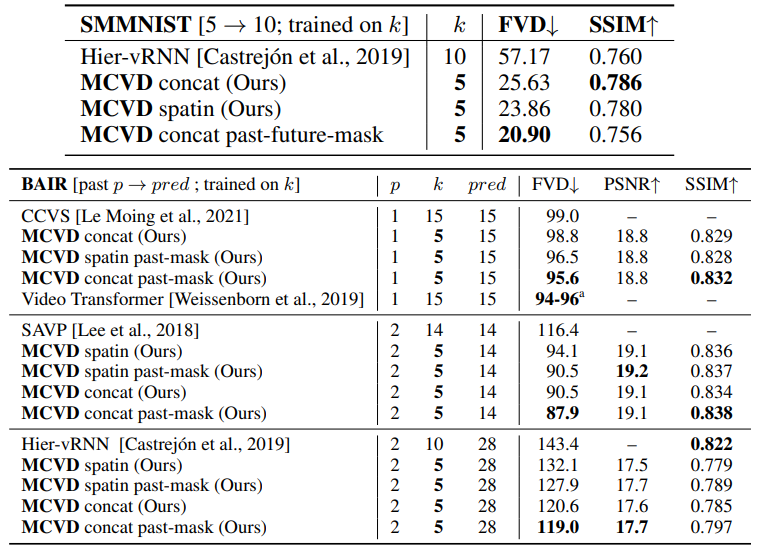
In practice, given enough capacity, we observe that our more general models (trained with past and future frames with masking), actually perform better than our specialized models (trained only for one task)! 🧙 This means that training Generalists is more beneficial than training Specialists! See Figure 6 below for some examples of this. Note that we are still running some general models as the paper contains fewer models with future-frames masking; we will keep everyone up-to-date as new results arrive.
Now, this is all great and impressive, but are there limitations to this approach? The main limitation of our work is limited compute. We are from academia, and thus we were limited by Compute Canada infrastructure, which is 1 to 4 GPUs (with extremely long queue times for 4 GPU models and lots of shutdowns at the worst times possible 😹). Given our GPU constraint, our number of parameters was limited, and thus we could not reach the state-of-the-art on unconditional generation for very hard datasets such as UCF-101. See Figure 7 below.

Furthermore, to ensure comparisons to existing results on prediction baselines (on SMMNIST, BAIR, Cityscapes), we used the same amount of starting frames as conditioning frames (5 for SMMNIST, 1-2 for BAIR, 2 for Cityscapes) as other papers used. Although we obtain high quality on even long-term videos, limiting the number of previous frames in such a way limits our long-term consistency. For example, in SMMNIST, when two digits overlap during 5 frames, a model conditioning on 5 previous frames will have to guess what those numbers were before overlapping, so they may change randomly. See an example below.
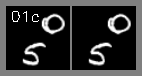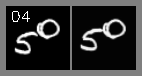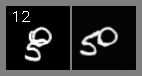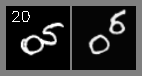
Nevertheless, despite our compute limitations, our models have excellent quality/diversity, and they improve a lot through scaling! 😎 Thus, we encourage users with access to massive resources to scale our method beyond our 4 GPUs limit. The masking approach is extremely powerful; it’s just a matter of significantly increasing the number of conditioning (past and future) frames and the number of channels/layers! STACK MORE LAYERS.

Contrary to some of our competitors 😉, our code and checkpoints will be fully open-source (we are finalizing the code; we will release it within the end of the week)! 😻
Website with lots of video samples

Hi Alexia,
I have a question about the SPATIN-based model.
From reading the codebase, it seems like there is a unique SPADE model (or layer, not what I should call it) initialized for each time we apply a groupnorm?
Is it possible to explain why this is done?
Have you considered the possibility of using only one shared SPATIN model that injects the past/future frame info into the U-Net blocks?
Thanks.
LikeLike
Sorry for the long delay, I am rarely on WordPress. Yes, to me the one shared SPATIN makes more sense, less memory expensive, and seems like it could generalize better. It’s definitively worth trying in my opinion.
LikeLike