Since AlexNet showed the world the power of deep learning, the field of AI has rapidly switched to almost exclusively focus on deep learning. Some of the main justifications are that 1) neural networks are Universal Function Approximation (UFA, not UFO 🛸), 2) deep learning generally works the best, and 3) it is highly scalable through SGD and GPUs. However, when you look a bit further down from the surface, you see that 1) simple methods such as Decision Trees are also UFAs, 2) fancy tree-based methods such as Gradient-Boosted Trees (GBTs) actually work better than deep learning on tabular data, and 3) tabular data tend to be small, but GBTs can optionally be trained with GPUs and iterated over small data chunks for scalability to large datasets. At least for the tabular data case, deep learning is not all you need.
In this joint collaboration with Kilian Fatras and Tal Kachman at the Samsung SAIT AI Lab, we show that you can combine the magic of diffusion (and their deterministic sibling conditional-flow-matching (CFM) methods) with XGBoost, a popular GBT method, to get state-of-the-art ✨ tabular data generation and diverse data imputations 🤯.

Score-based diffusion models are powerful techniques to generate data; they work by transforming real data into noise through a forward stochastic process and learning to reverse the process from noise to data. Conditional-flow-matching (CFM) methods work similarly but do so in a deterministic fashion (moving deterministically from both data to noise and noise to data).
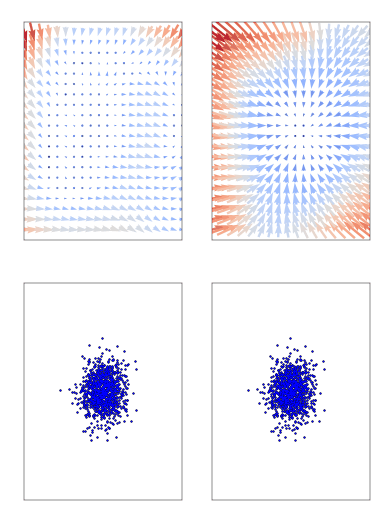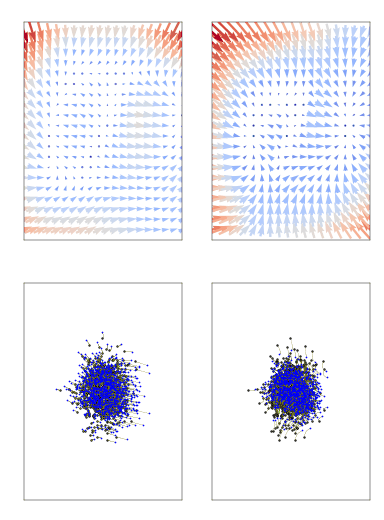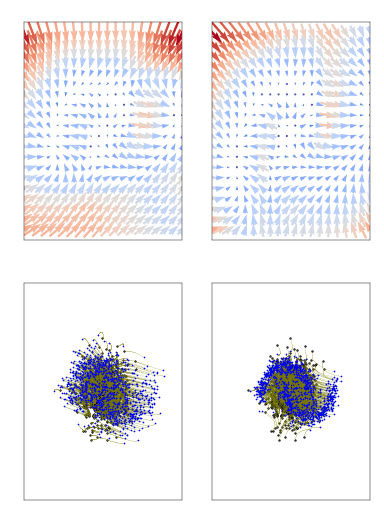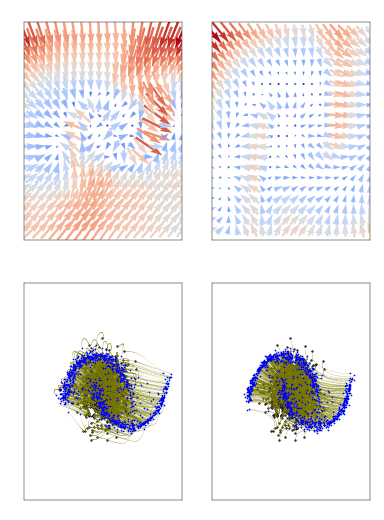
(from https://github.com/atong01/conditional-flow-matching)
For both flow and diffusion models, the objective function is a least-square loss function conditional on time (t=0 is real data, t=1 is pure noise), which is summed over each variable/feature (since its a vector field). We train XGBoost regression models as replacements from neural networks to minimize these losses. We train one model per variable/feature (p) and time t (t = 0, 1/n_t, 2/n_t, …, 1; for a total of n_t=50 different time values). For categorical data, we treat them as dummy variables and round them to the nearest class after generation.
Diffusion and flow-based models usually rely on mini-batch training with deep learning. This means that random Gaussian noise is sampled during training of the same size as the real data, and it is used to calculate the noisy data (moving from real data to noise) at time t. Since XGBoost needs the full data, we cannot rely on mini-batches. In order to associate multiple different noise samples per real data sample, we duplicate the rows of the real data K times (going from size [n,p] to size [nK,p]) and then generate noise data of the same shape. Then, we compute the forward diffusion/flow step for each time t. See the paper for more details on the algorithm.
A lot of the tabular data generation/imputation papers focus only on one or two machine learning metric(s). We take a broader approach by building a very thorough and difficult benchmark using 24 datasets and tackling four quadrants of metrics: closeness in distribution, diversity, prediction, and statistical inference.
The main results for generation are shown below (our methods are Forest-VP and Forest-Flow):

As can be seen, our method obtains incredible performance across all metrics. See the paper for more experiments and explanation of the different metrics.
Missing data
Amazingly, XGBoost is naturally able to handle missing values through careful splitting. Thus, our method can be used to generate new samples (with no missing values) while trained on data with missing values! We can also use our method for imputing missing values. See the paper for more details.
Choice of tree-based method
Our method can be used with any type of tree-based method. In practice, we found XGBoost and LightGBM to perform best, but XGBoost is much faster due to its efficient parallelization, so we use it exclusively.

Paper with code
Check our paper for more details!
To make it accessible to everyone (not just AI researchers but also statisticians, econometricians, physicists, data scientists, etc.), we made the code available through a Python library (on PyPI) and an R package (on CRAN). See our Github for more information. [Note: The R code will be released soon]

3 thoughts on “Fashion repeats itself: Generating tabular data via Diffusion and XGBoost 🌲”